
Raft Consensus Protocol - FizzBee Specification for Reasoning
Design documents typically serve two main purposes:
- To act as a guide or blueprint for implementation.
- To explain why the design is correct and why each part is necessary.
The first goal is often achieved through pseudocode and illustrations. The second is usually addressed with detailed prose, examples, and counterexamples that highlight the need for specific design choices.
Formal specifications, such as those written using FizzBee, can serve both of these goals as well. But depending on which goal we’re pursuing, the structure and level of abstraction in the specification can vary significantly.
In a previous example, we used FizzBee to formally specify the Raft consensus protocol in a way that developers could follow as an implementation guide. We also demonstrated how to prove key safety properties and verify correctness. While that form is easy for developers to understand, it can be verbose.
In this document, we shift focus to the second goal: reasoning about the design and proving it correct.
The motivation for this Reasoning Style is speed and brevity. When proposing or refining a design, we often want to uncover flaws early before committing to details. This means modeling the essential ideas while skipping over operational details like message formats or RPC mechanics. Since many of these lower-level effects are already internalized by the designer, we abstract them out and directly model their consequences. When we do that, the model checker can explore the design space more efficiently and quickly identify potential issues. This makes trial and error iterations faster, allowing us to refine the design without getting bogged down in implementation details.
In a later article, we will show how to convert this reasoning spec into an implementation guide that developers can follow. And, prove the implementation style and the reasoning style are equivalent by refinement.
- Raft is a leader-based consensus algorithm.
- The leader is elected by a majority of the nodes in the cluster.
- There will be a single leader per term
- Only the leader can accept writes from the clients.
- Leader decided when to commit a log entry.
- The leader elected will be the node that is more up-to-date than the majority of the nodes in the cluster.
- A leader can only directly commit the log entry from its current term, not from the previous term. (They are committed indirectly, when the new term’s log is committed)
The eventual goal is to prove:
- In the entire system, committed entries in the log will monotonically increase.
- Each node will apply the log entries in the same order.
Since our goal here is reasoning and validating correctness—not implementation—we’ll significantly abstract the details to focus on the core logic of the algorithm. If we were explaining this to a colleague on a whiteboard, we might sketch something like this:

The state variables of each node
- There are multiple nodes.
- Each node has a log, that is a list of entries and current term.
- Globally, since we will have a single leader per term, we will represent them as a list of leaders, where the index is the term number.
Although, we could express the leader as property within each node, it would be difficult to express for a single them there is only one leader. So, this representation simplifies that property.
Run the following code in the playground.
“Run in playground” will open the snippet in the playground.
Then, click “Enable whiteboard” checkbox and click Run.
The screenshot of the playground highlighting the Enable whiteboard and Run steps
|
|
When you run it, you’ll see an The screenshot of the playground highlighting the Explorer link to open the Explorer viewExplorer link. Click you’ll see an explorer.
At present, it will only show the init state. As we start filling in the details, you’ll see more interactive exploration.

The screenshot of the Explorer view with the initial states of the Raft specification
Here, actions imply the changes that could happen in the system. These are the changes that could happen:
- A term can progress without electing a leader
- A node can become a leader.
- A node can receive a command from the client and append it to its log.
- A node can copy a log entry from the leader.
- A node can commit a log entry.
|
|
When you run it, it will show these actions defined. At present, the actions do nothing when you click.
You’ll eventually see the states change with the actions.
The screenshot of the Explorer view with the defined actions
Let’s start with the simplest action. A term could pass by without electing a leader. This is a valid state transition, and we will model it as an atomic action. Since this is a monotonically increasing system, this won’t converge. So, we can simply define a maximum number of terms.
# Add this along with the constants at the top
MAX_TERMS = 3
# Add this as a global action along with Init
atomic action NoLeaderElection:
require len(leaders) <= MAX_TERMS
leaders.append("")
For now, let’s start with a naive logic. Any node can become a leader at any point in time.
role Node:
# ...
atomic action BecomeLeader:
require len(leaders) <= MAX_TERMS and leaders[-1] != self.__id__
# TODO: Only a node with most up-to-date log can become a leader.
# TODO: Also, at least NUM_NODES//2 nodes should have its currentTerm updated as they would have voted
self.currentTerm = len(leaders)
leaders.append(self.__id__)
Commands can only be submitted to the leader. Due to various reasons, command could arrive at the stale leader.
So instead of checking, if the current node is the leader of the latest term, we will check if the current node is
the leader of its current term with leaders[self.currentTerm] == self.__id__.
For commands, since we don’t really care what they are, we could simply use a counter to represent the command. After each command, we will increment the counter and append it to the log.
Finally, to limit the number of commands, we will define a constant MAX_CMDS and check if the next command is less than that.
MAX_CMDS = 3
role Node:
# ...
atomic action SubmitCommand:
require leaders[self.currentTerm] == self.__id__ and nextCmd < MAX_CMDS
term = self.currentTerm
nextCmd = nextCmd + 1
self.log.append( (term, nextCmd) )
action Init:
nextCmd = 0
# ... remaining Init action
|
|
When a node becomes a leader, it will have the most up-to-date log. So, other nodes should copy the log entries from the leader.
However, due to network delay and other reasons, messages might be delayed. So, for any node, that is not a leader, it could copy a new log entry from any leader of any term that is greater than or equal to its current term.
When writing the formal spec as a guide to implementation, we would be talking about the RPCs and message parameters and so on, But in this spec since we are working on spec for reasoning, we can skip how the messages arrive and so on. Instead only look at what message can be copied, and how to do it.
role Node:
# ...
atomic action AppendEntries:
# Find the possible log entries to be copied
# arbitrarily select one of those (any keyword)
# Update the currentTerm to the term of the leader from which it is copied
# append the log entry to the log.
Find the leaders of terms >= currentTerm and exclude the terms where no leader was elected, id!="" and only from a different leader id != self.__id__.),
term_leaders = { t:id for t,id in enumerate(leaders) if t >= self.currentTerm and id and id != self.__id__}
Now, to explore the terms, we can use any keyword to select one of the terms.
term_leader = any term_leaders.items()
term = term_leader[0]
leader = resolve_role(term_leader[1])
We could’ve simply used,
term = any term_leaders
leader = resolve_role(leaders[term])
When using the explorer UI, the first option would show both the term and the leader id, whereas the second option would only show the term. If you don’t care about the explorer, the first option works well.
To copy the log, there could be two cases:
- The self.log is a strict subset of leader.log, so we can simply append the next entry.
- The self.log has diverged from the leader.log (probably because a new leader elected), then, we must truncate the current log to match common prefix, then append the new entry.
Identify the first entry that diverges from the leader’s log .
for i in range(len(leader.log)):
if len(self.log) <= i:
# self.log is a subset of leader.log
break
if self.log[i] != leader.log[i]:
# log has diverged, so truncate and keep until the i-1th entry
# self.log = self.log[:i]
break
Finally, truncate and append the new entry.
# At this point, leader.log[i] is the entry that must be inserted at self.log[i] and exclude everything after that.
# Note: If the log was already equal, this becomes a no-op, and only currentTerm might get updated, equivalent to a heartbeat.
self.log = self.log[:i]
self.log.append(leader.log[i])
self.currentTerm = term
Here is the fizzbee spec so far.
|
|
This is the core of the consensus algorithm. A log entry is committed when a majority of the nodes have the same log entry. Now, before we implement the with the precise logic, let us get an incorrect, rough implementation. Then, debug our way to deriving all the crucial decisions made to implement the algorithm.
In the raft implementation and the previous spec, each node maintains a commit index. For this reasoning spec, suitable for understanding, I believe, maintaining a global committed log is simpler and easier to reason about because, similar to who the leader of a term is, what entries are committed is also a global property.
So, let us add a global variable committed that is a list of log entries that are committed.
action Init:
# ... along with other variables
committed = [] # List of committed log entries
A leader can only commit log entries if the log entry is replicated to a majority of the nodes.
There is a nuance that the raft paper specifically addresses in section 5.4.2, which is that a leader can only commit log entries from its current term. We will address this later.
To implement the commit logic, we will iterate through all the nodes, and count the number of nodes that have the same log entry as the current node’s log entry.
indexCounts = [0] * len(self.log)
for n in nodes:
for i in range(min(len(self.log), len(n.log))):
if n.log[i] == self.log[i]:
indexCounts[i] += 1
Now, we will iterate through the indexCounts in reverse order and find the first index that has a count greater than NUM_NODES//2
for i in reversed(range(len(indexCounts))):
if indexCounts[i] > NUM_NODES//2 and i >= len(committed):
committed = self.log[0:i+1]
return
Now, the commit action looks like this:
atomic action Commit:
# This spec has a bug, and the raft protocol specifically addresses this in section 5.4.2
# TODO: We will fix this later.
require self.__id__ == leaders[self.currentTerm]
indexCounts = [0] * len(self.log)
for n in nodes:
for i in range(min(len(self.log), len(n.log))):
if n.log[i] == self.log[i]:
indexCounts[i] += 1
for i in reversed(range(len(indexCounts))):
if indexCounts[i] > NUM_NODES//2 and i >= len(committed):
committed = self.log[0:i+1]
return
# Commit is not possible, so require False removes this state transition.
require False
Here is the specification so far. Open the playground, enable explorer and click Run.
It generates around 31,000 node state graph with around 10,000 unique states.
|
|
Click on the explorer link. Now, try clicking on various buttons and see how the states change.
You might notice some issues.
The scenario is,
-
Node 0 becomes the leader, receives an entry, replicates to Node 1, commits this entry.
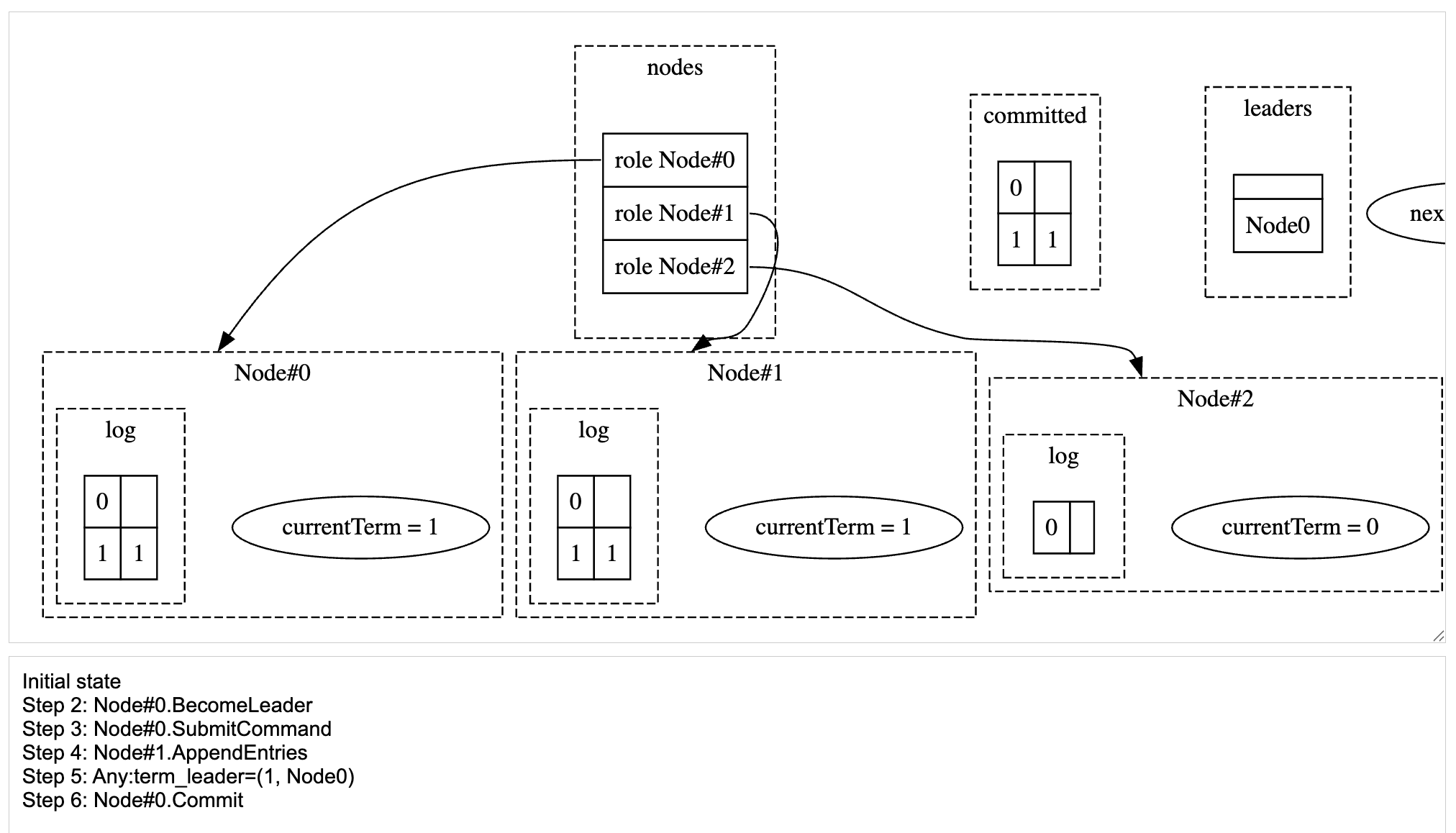
Node#0 committed cmd1 after replicating to Node#1
-
Node 0 goes offline.
-
Node 2 becomes the leader, replicates to Node 1. At this point, both Node 1 and Node 2 has the same log entry 2. But Node 0 has previously committed entry 1, but it is not present in any active node’s log.
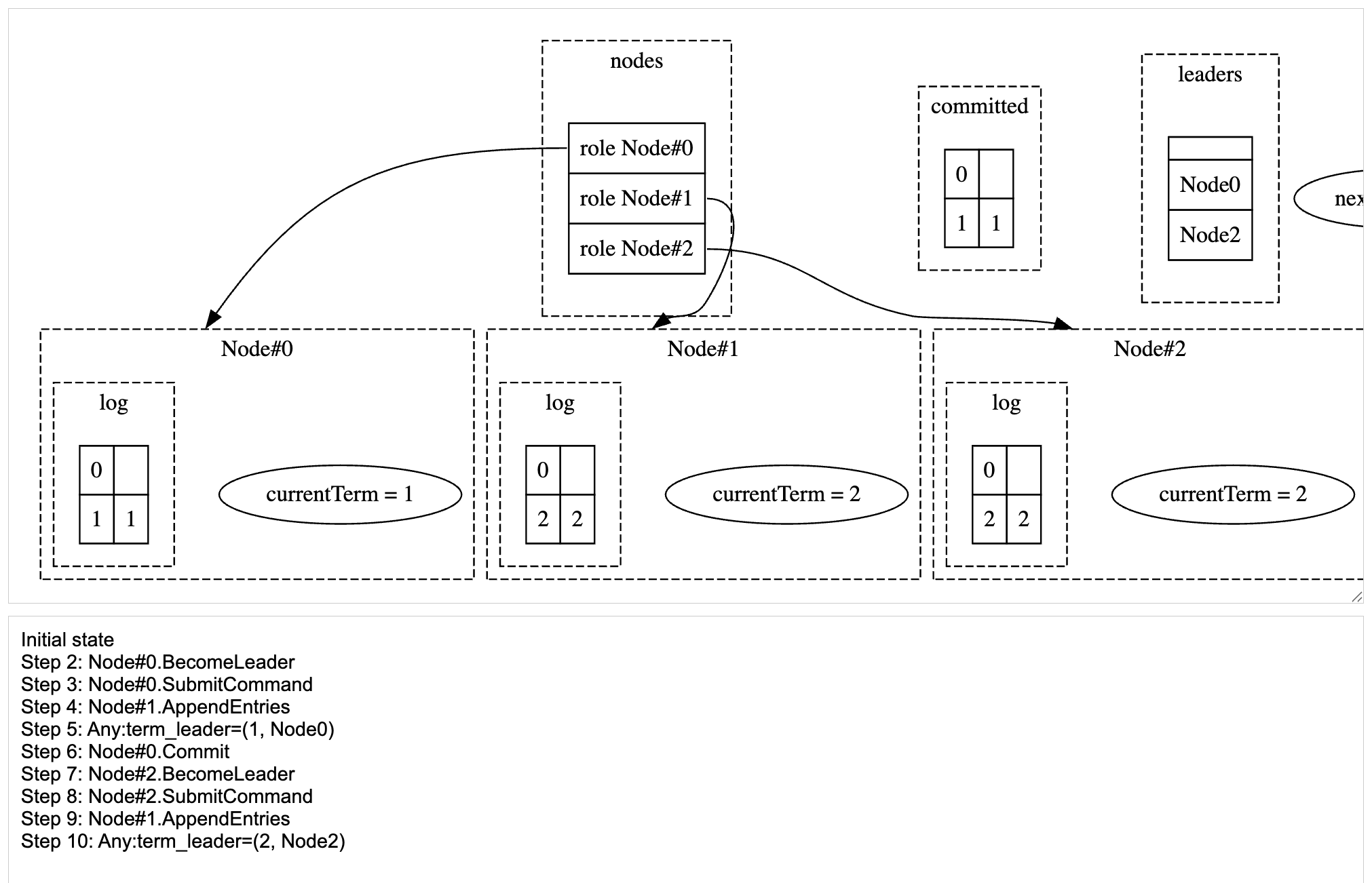
Node#2 after replicating cmd2 to Node#1
It can get worse. After Node 0 comes back online, it will receive the AppendEntries from Node 2, and it will truncate its log to match the common prefix, which is empty, and it will lose the committed entry 1.
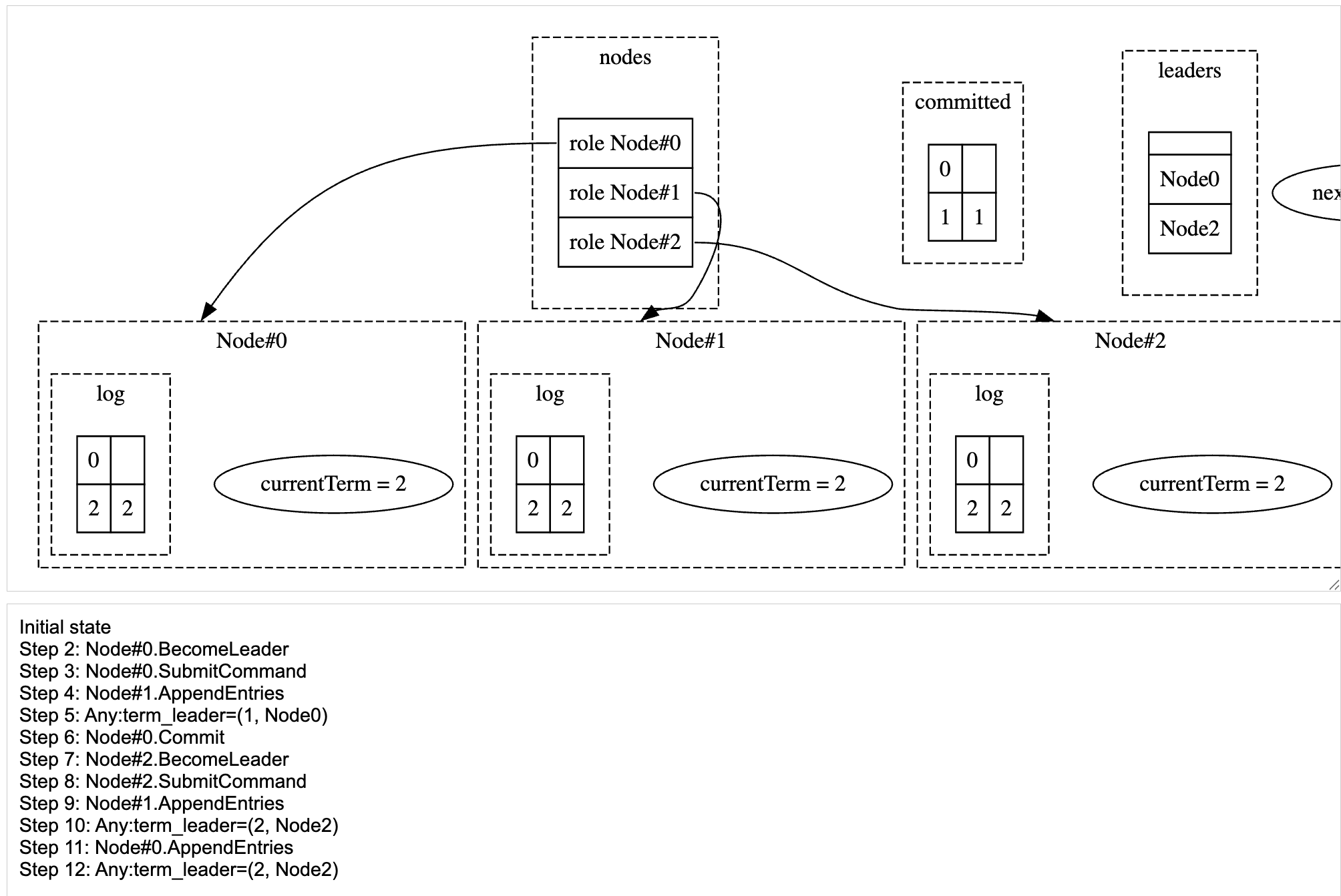
Node#0 after replacing cmd2 in its log
This is an obvious issue, and leader based consensus algorithms like Multi-Paxos and Raft addresses these differently. In Multi Paxos, any server can win election. The winner transfers missing log entries from its peers before becoming leader. Whereas, in Raft, the leader will always include the committed entries. It does it by ensuring, a node will vote for a candidate only if the candidate’s log is at least as up-to-date as its own log.
But before fixing it, let us add assertions to identify these issues automatically.
While we can explore manually to get a sense of the issues, it would be better to add assertions that will automatically identify these issues.
The raft paper lists 5 safety properties.
- Election Safety: at most one leader can be elected in a given term. §5.2
- Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries. §5.3
- Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index. §5.3
- Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms. §5.4
- State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. §5.4.3

The screenshot of the Explorer view with the defined assertions
Of these, with the current spec, as we have represented leader as a global list indexed by term, invalid election state is not representable. Then, for the State Machine Safety, we have not represented the state machine, so we will skip that for now.
Let us add the remaining assertions one by one.
This is a transition assertion, that checks by comparing with the previous state.
In FizzBee, we can use the before and after variables to compare the state before and after the transition.
transition assertion LeaderAppendOnly(before, after):
for i in range(len(after.nodes)):
node = after.nodes[i]
if node.__id__ == after.leaders[node.currentTerm]:
# The node is a leader for its term.
if len(before.nodes[i].log) > len(node.log):
# some log entries deleted
return False
if node.log[:len(before.nodes[i].log)] != before.nodes[i].log:
# some log entry is updated
return False
return True
When you run with this assertion, you’ll notice that the assertion passes as we never delete or update log entries from the leaders.
This is a standard safety assertion. To implement,
- we will iterate through all pairs of nodes. We’re using standard python’s
itertools.combinations(nodes, 2)equivalent. Note: Not all itertools api are supported yet (Only combinations, combinations_with_replacements and permutations). - Then, we will pair up corresponding log entries. We’re using
zip(log1, log2)to pair up the log entries. - We’ll find the last entry that has matching term by iterating through the log entries in reverse order, so that we can find the last matching entry.
- Once matching term is found, all the entries before that must match.
always assertion LogMatching:
for node_pair in itertools.combinations(nodes, 2):
log1, log2 = node_pair[0].log, node_pair[1].log
matched = False
for entry_pair in reversed(zip(log1, log2)):
if not matched and entry_pair[0][0] != entry_pair[1][0]:
continue
else:
matched = True # Last log pair where index and term matched
if entry_pair[0] != entry_pair[1]:
return False
return True
This assertion also passes without any issues.
This is the crucial assertion required to ensure that the committed entries are never lost.
always assertion LeaderCompleteness:
for node in nodes:
if node.__id__ != leaders[node.currentTerm]:
continue
prevTermCommitted = [e for e in committed if e[0] <= node.currentTerm]
if len(prevTermCommitted) > len(node.log):
# some log entries might've been deleted
return False
if node.log[:len(prevTermCommitted)] != prevTermCommitted:
# Not a prefix
return False
return True
When you run this, you’ll notice that the assertion fails. Click on the explorer to see the states and the actions that led to this failure.
Initial state
Step 2: Node#0.BecomeLeader
Step 3: Node#0.SubmitCommand
Step 4: Node#1.BecomeLeader <-- Node#1 becomes the leader
Step 5: Node#2.AppendEntries <-- Node#2 accepts the log entry from Node#0
Step 6: Any:term_leader=(1, Node0)
Step 7: Node#0.Commit
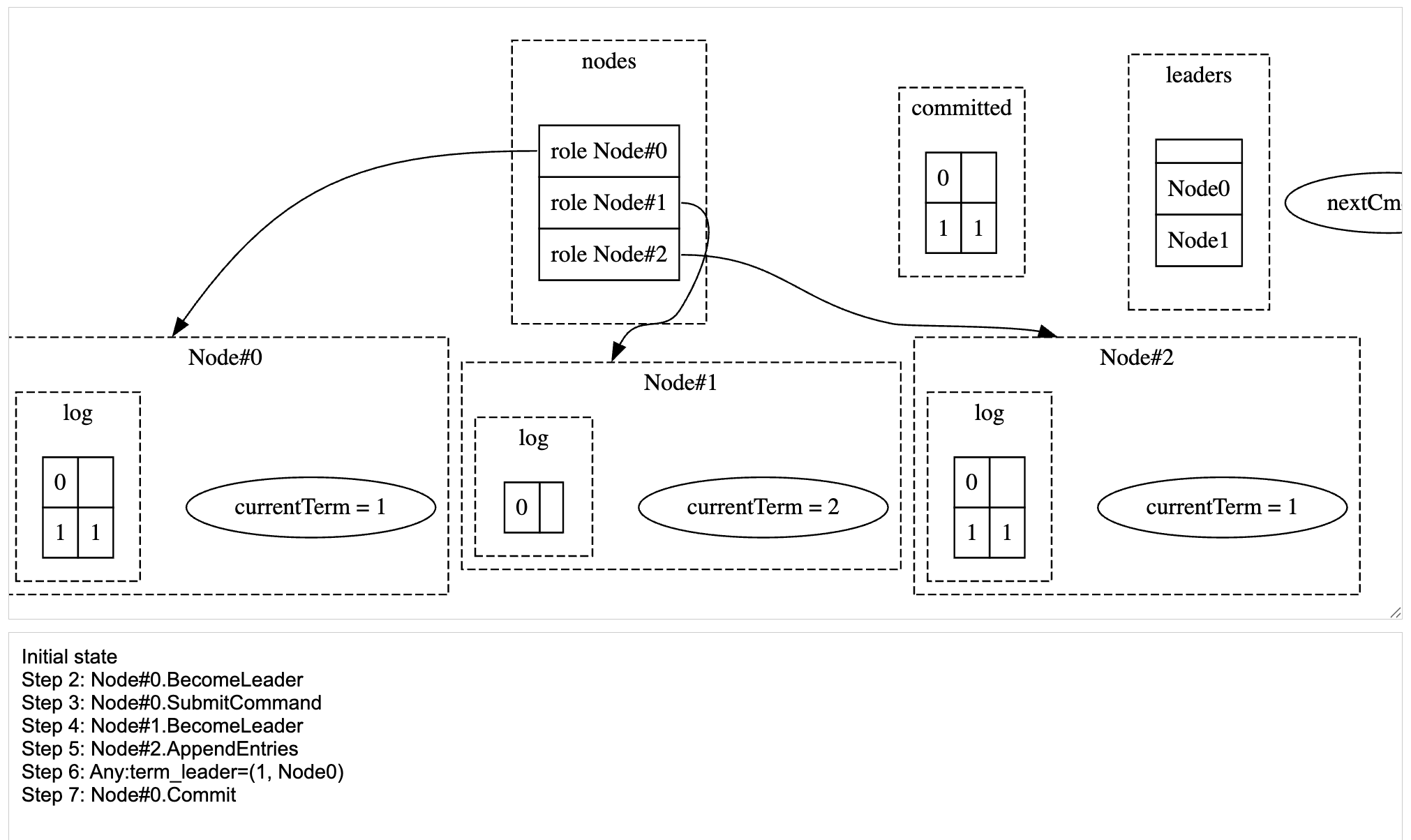
The screenshot of the Explorer view showing the Leader Completeness assertion failure
The issue happens because the old leader was allowed to commit the log entry even though a new leader was elected. This happened because, majority of the nodes accepted entries from old leader, even though a new leader was elected. This is because, at present, our leader election is pretty naive. In Raft, a node can become a leader only if they were accepted by a majority of the nodes in the cluster. As a side effect of the RequestVote RPC, every time a new election happens, the node would update the currentTerm to the term of the candidate that it voted for. And, stop accepting entries from the old leaders.
This is a little tricky. But the basic step is, if a leader is elected, then at least half the nodes in the cluster must have voted for it. That means, half the nodes in the cluster must have their currentTerm updated to the term of the new leader.
Any combination of nodes could vote. If there are 5 nodes,
- then at least 3 nodes must have their currentTerm updated to the term of the new leader.
- and 1 of the nodes must be the new leader. So, let us create a small helper function, to get all possible combinations of nodes.
def all_combinations(objects, min_len, max_len):
s = []
for i in range(min_len, max_len+1):
for p in itertools.combinations(objects, i):
s.append(p)
return s
You can then try this on python console.
# python
Python 3.12.0 (v3.12.0:0fb18b02c8, Oct 2 2023, 09:45:56) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import itertools
>>> def all_combinations(objects, min_len, max_len):
... s = []
... for i in range(min_len, max_len+1):
... for p in itertools.combinations(objects, i):
... s.append(p)
... return s
...
>>> a = [1, 2, 3, 4]
>>> all_combinations(a, len(a)//2, len(a))
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4), (1, 2, 3), (1, 2, 4), (1, 3, 4), (2, 3, 4), (1, 2, 3, 4)]
>>>
>>> a=[1,2]
>>> all_combinations(a, len(a)//2, len(a))
[(1,), (2,), (1, 2)]
>>>
If there are 5 nodes, [0, 1, 2, 3, 4] and for 0 to become a leader, in addition to 0’s vote, it must secure, either of these combinations: [(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4), (1, 2, 3), (1, 2, 4), (1, 3, 4), (2, 3, 4), (1, 2, 3, 4)]
This will address one of the TODOs.
Find the eligible votes for the current node to become a leader. For now, let us make, any node can still become a leader. And any other node can vote for it.
eligible_votes = [n.__id__ for n in nodes if n != self]
Get all combinations of eligible votes, where the length of the combination is at least NUM_NODES//2.
voting_set = all_combinations(eligible_votes, NUM_NODES//2, NUM_NODES)
Finally, update the currentTerm of the nodes that voted for the new leader.
for n in nodes:
if n.__id__ in voters:
n.currentTerm = self.currentTerm
So, the final BecomeLeader action looks like this:
atomic action BecomeLeader:
require len(leaders) <= MAX_TERMS and leaders[-1] != self.__id__
# TODO: Only a node with most up-to-date log can become a leader.
eligible_votes = [n.__id__ for n in nodes if n != self]
voting_set = all_combinations(eligible_votes, NUM_NODES//2, NUM_NODES)
voters = any voting_set
self.currentTerm = len(leaders)
for n in nodes:
if n.__id__ in voters:
n.currentTerm = self.currentTerm
leaders.append(self.__id__)
This will fix the first issue, but it will show a newer issue. You can see from the explorer that Node#2 doesn’t have the committed entry, but it is still able to become a leader.
Initial state
Step 2: Node#0.BecomeLeader
Step 3: Any:voters=(Node1,)
Step 4: Node#0.SubmitCommand
Step 5: Node#1.AppendEntries
Step 6: Any:term_leader=(1, Node0)
Step 7: Node#0.Commit <-- Node#0 commits the entry after replicating it to just Node#1.
Step 8: Node#2.BecomeLeader
Step 9: Any:voters=(Node0,) <-- Node#2 becomes the leader with vote from Node#0
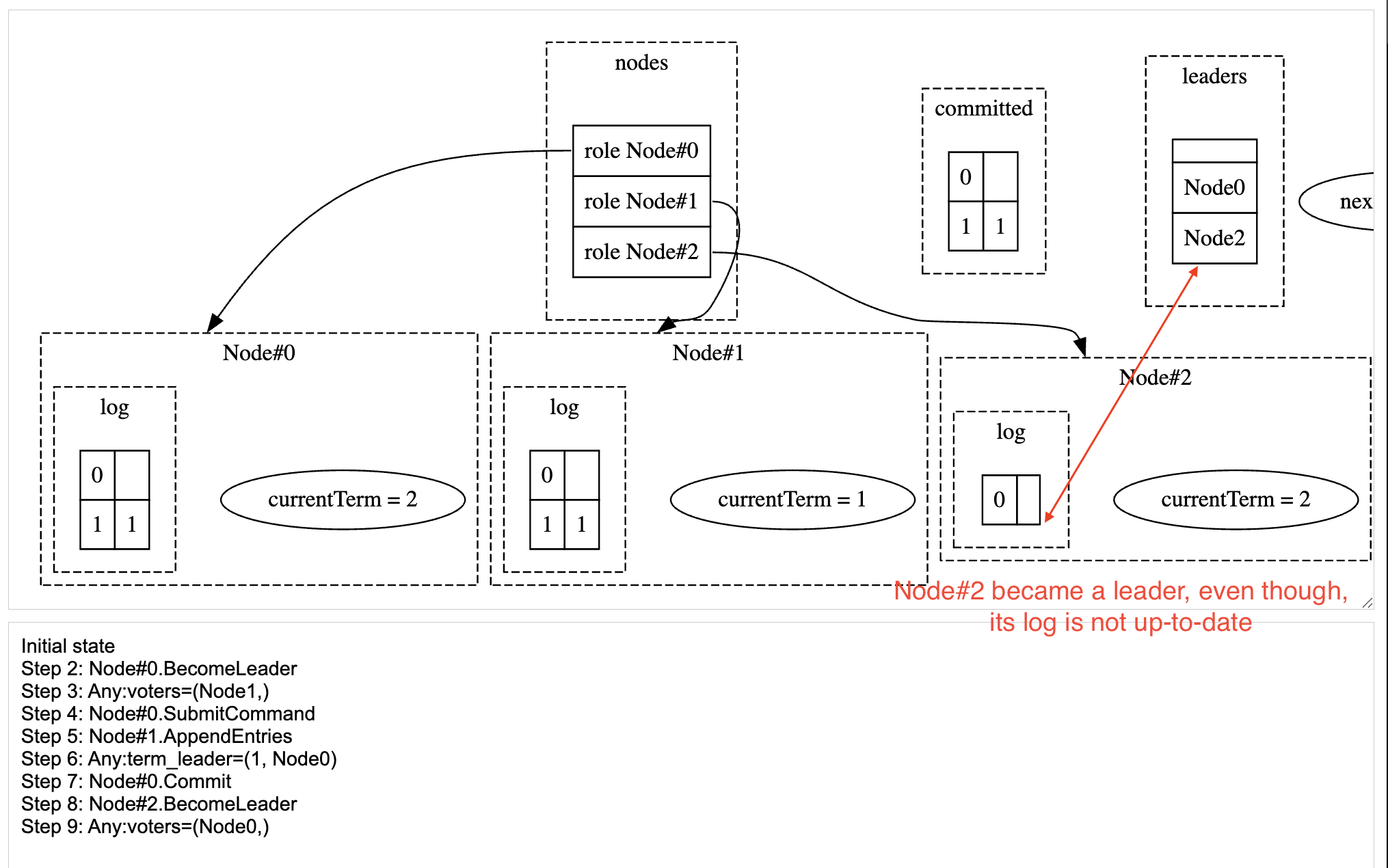
The screenshot of the Explorer view showing the Leader Completeness assertion failure after fixing the first issue
This will address the first TODO in the BecomeLeader action. Raft protocol specification addresses this issue, by limiting who can become a leader. This is done by limiting who can vote for a new candidate. A node can vote for a candidate if and only if the candidate’s log is at least as up-to-date as its own log. It must satisfy one of these 2 conditions.
- Last log entry’s term of the candidate must be at least as recent as the last log entry’s term of the voter.
- If the last log entry’s term is the same, then the candidate’s log must be at least as long as the voter’s log.
Let’s define the condition as a function.
role Node:
# ...
def is_eligible_voter(self, other):
""" Returns true if the other node's log is at least as up-to-date as the self.log
"""
return (self.log[-1][0] > other.log[-1][0]
or (self.log[-1][0] == other.log[-1][0] and len(self.log) >= len(other.log)))
and update the line defining eligible_votes to
eligible_votes = [n.__id__ for n in nodes if n != self and self.is_eligible_voter(n)]
When you run it, it will pass all the invariants. But there is still an issue that will show up when you increase
the MAX_TERMS to 4. When you run it, you’ll notice that the LeaderCompleteness assertion fails again with a new issue.
Initial state
Step 2: Node#0.BecomeLeader
Step 3: Any:voters=(Node1,)
Step 4: Node#0.SubmitCommand
Step 5: Node#1.BecomeLeader
Step 6: Any:voters=(Node2,)
Step 7: Node#1.SubmitCommand
Step 8: Node#0.BecomeLeader
Step 9: Any:voters=(Node2,)
Step 10: Node#2.AppendEntries
Step 11: Any:term_leader=(3, Node0)
Step 12: Node#0.Commit
Step 13: Node#1.BecomeLeader
Step 14: Any:voters=(Node0,)
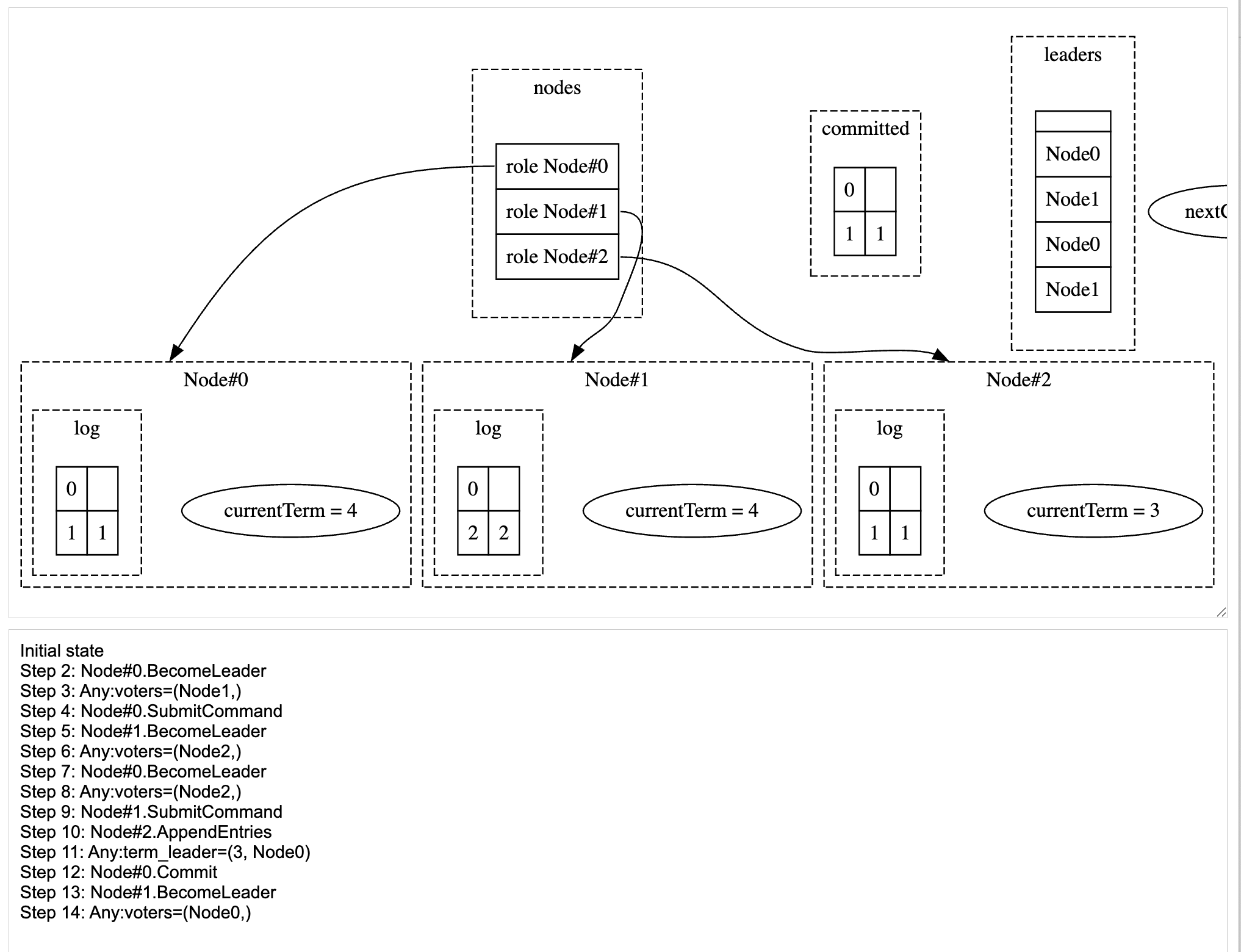
The screenshot of the Explorer view showing the Leader Completeness assertion failure after fixing the second issue
What happens here is,
- Node 0 and Node 1 become leaders in terms 1 and 2 respectively, and added separate log entries each.
- Node 0 became the leader in term 3 with vote from Node 2.
- Then, it replicated its log entry from term 1 to Node 2.
- Since this log from term 1 is replicated to the majority, it committed the entry 1.
- Then, Node 1 became the leader in term 4 with vote from Node 0.
At this point the log entry committed by Node 0 in term 3 is not present in Node 1’s log. It found the violation here, but (if the system had continued without stopping after the failure),
- Then, Node 1 would’ve replicated its log entry from term 2 to Node 2 overwriting it’s term 1 log entry.
- Node 1 would see, this new log is replicated to the majority, so it would commit the entry 2.
The Raft paper shows this violation in section 5.4.2, and it is a crucial part of the Raft protocol.
This is a complex scenario to identify without exhaustive checking showcases the power of formal methods.
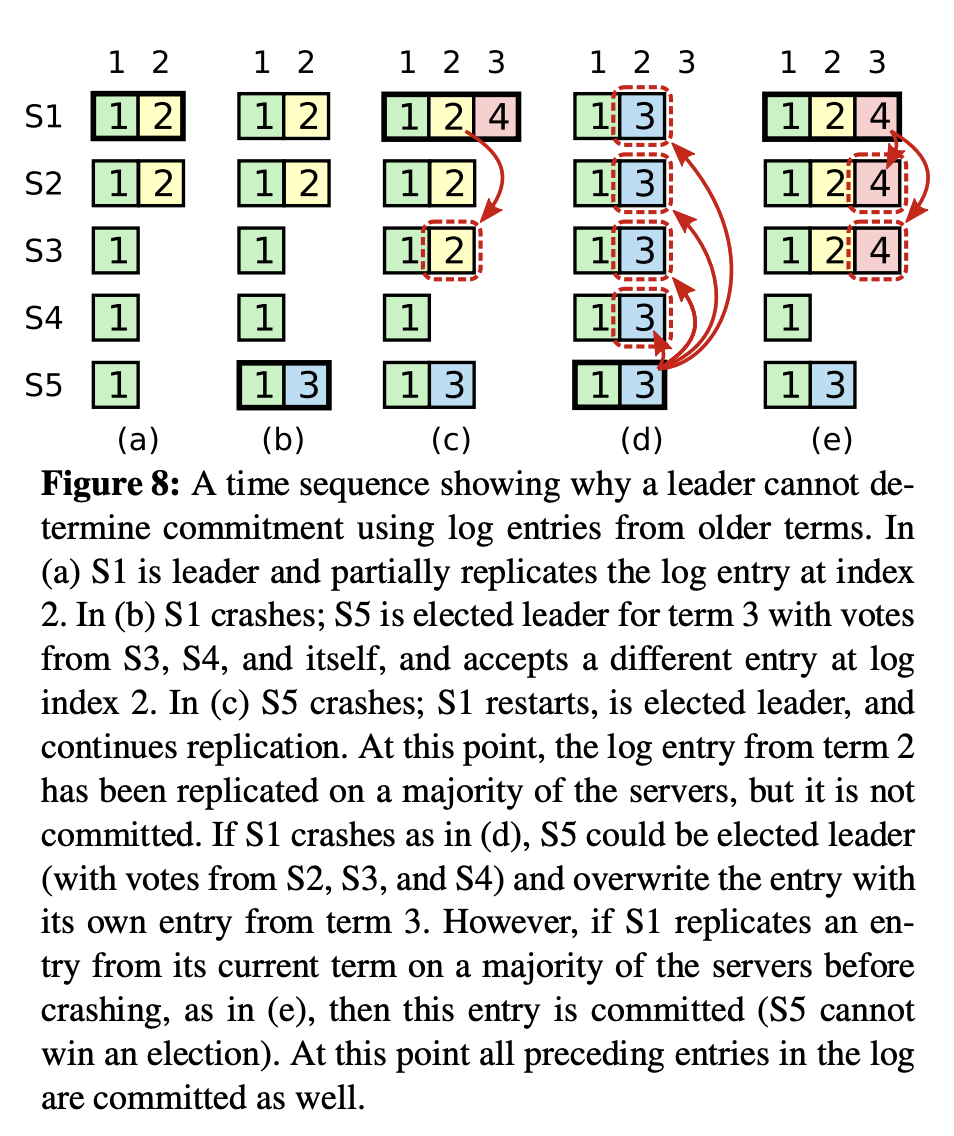
The screenshot form the Raft paper showing the potential issue with committing from previous terms
The Raft paper describes this issue in section 5.4.2, and it is a crucial part of the Raft protocol.
The screenshot form the Raft paper showing the fix that a leader can commit a log only from its current term
As noted in the attached screenshots of the Raft paper, at present, the leader determines commitment of log entries from previous terms by counting replicas. Instead, the leader should only commit log entries from its current term by counting replicas.
In other words, if the log does not contain any entry from the leader’s current term, then it should not commit any log entries. So, a new leader can only commit if a new log in its current term is successfully replicated to a majority of the nodes.
So the fix is, in the commit action, we are checking if the log at an index
matches the leader’s log with n.log[i] == self.log[i]. But we need to limit to the log
from the leader’s current term simply by checking n.log[i][0] == self.currentTerm.
Due to the LogMatching property (if index and term match, then command also matches), we could skip checking if the logs match with the leader’s log.
Now, the commit action looks like this:
atomic action Commit:
require self.__id__ == leaders[self.currentTerm]
indexCounts = [0] * len(self.log)
for n in nodes:
- for i in range(min(len(self.log), len(n.log))):
- if n.log[i] == self.log[i]:
+ for i in range(len(n.log)):
+ if n.log[i][0] == self.currentTerm:
indexCounts[i] += 1
for i in reversed(range(len(indexCounts))):
if indexCounts[i] > NUM_NODES//2 and i >= len(committed):
committed = self.log[0:i+1]
return
# Commit is not possible, so require False removes this state transition.
require False
When you run this, it will pass all the invariants, and you can see that the committed entries are never lost.
Note: You might have to run this on your local machine, as the playground has a time and memory limit for the model checking.
Model checking BuzzyMcBee.json
configFileName: fizz.yaml
StateSpaceOptions: options:{max_actions:100 max_concurrent_actions:2 crash_on_yield:true} liveness:"strict" deadlock_detection:false
Nodes: 20000, queued: 68761, elapsed: 8.108796666s
Nodes: 40000, queued: 117469, elapsed: 16.6282675s
Nodes: 60000, queued: 154283, elapsed: 25.365888291s
Nodes: 80000, queued: 184525, elapsed: 34.342376916s
Nodes: 100000, queued: 210291, elapsed: 43.532066083s
Nodes: 120000, queued: 222071, elapsed: 52.902323083s
Nodes: 140000, queued: 232069, elapsed: 1m2.568254083s
Nodes: 160000, queued: 243988, elapsed: 1m12.225990583s
Nodes: 180000, queued: 235181, elapsed: 1m21.77870425s
Nodes: 200000, queued: 232185, elapsed: 1m31.619472s
Nodes: 220000, queued: 226945, elapsed: 1m41.461837s
Nodes: 240000, queued: 193269, elapsed: 1m51.665684791s
Nodes: 260000, queued: 162823, elapsed: 2m1.679664583s
Nodes: 280000, queued: 131093, elapsed: 2m12.317908375s
Nodes: 300000, queued: 88841, elapsed: 2m24.726775791s
Nodes: 320000, queued: 43861, elapsed: 2m38.838144541s
Nodes: 328900, queued: 0, elapsed: 2m44.577233458s
Time taken for model checking: 2m44.57724975s
Skipping dotfile generation. Too many Nodes: 328900
Valid Nodes: 328900 Unique states: 99487
IsLive: true
Time taken to check liveness: 2.07964825s
PASSED: Model checker completed successfully
@@ -6,7 +6,7 @@
MAX_CMDS = 3
MAX_TERMS = 4
-role Node:
+symmetric role Node:
action Init:
# List of log entries. Each entry is a tuple of (term, cmd)
self.log = [(0, "")] # Adding a 0th entry as a sentinel to simplify implementation.
@@ -78,7 +78,7 @@
return
# Commit is not possible, so require False removes this state transition.
require False
-
+
atomic action NoLeaderElection:
require len(leaders) < MAX_TERMS
@@ -88,18 +88,18 @@
nextCmd = 0
leaders = [""] # Term starts with 1, so adding an "" as a sentinel to make it easier
committed = []
- nodes = []
+ nodes = set()
for i in range(NUM_NODES):
- nodes.append(Node())
+ nodes.add(Node())
transition assertion LeaderAppendOnly(before, after):
- for i in range(len(after.nodes)):
- node = after.nodes[i]
+ before_nodes_by_id = {node.__id__: node for node in before.nodes}
+ for node in after.nodes:
if node.__id__ == after.leaders[node.currentTerm]:
# The node is a leader for its term.
- prev = before.nodes[i]
+ prev = before_nodes_by_id[node.__id__]
if len(prev.log) > len(node.log):
# some log entries deleted
return False
With symmetry reduction, the interactive explorer will not work as expected.
For example: From the init state, if
Node#0becomes a leader with votes fromNode#1andNode#2, is equivalent toNode#1orNode#2becoming a leader with votes fromNode#0andNode#2orNode#0andNode#1respectively. So, in the interactive explorer if you selectNode#1.BecomeLeaderorNode#2.BecomeLeader, it will show the state as ifNode#0became the leader.This issue will be addressed eventually.
|
|
The state machine safety assertion is not implemented in the above spec. In the Raft paper, it is defined as:
State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index. §5.4.3
Implement this assertion in the spec.
Tips:
- Since this is a Node level assertion, you can define a applied_log as a state variable in each Node.
- In each node, create an action ApplyLog, that appends the committed log entry from the node’s log to the applied_log.
- Add the assertion that, the applied_log of all the nodes must be identical or a strict subset of one another.
One useful liveness property is that, a leader will eventually commit its log entry. This is a tricky one. The Raft paper does not define any liveness properties, but it is important to ensure that the system makes progress. It also does not show how to ensure that a leader will eventually commit its log entry.
Tips:
- Define the liveness assertion and see the error trace.
- Since the leader can only commit log entries from its current term, a leader must add a dummy value to its log entry in its current term if there is no new entries. Then, the protocol would handle committing the dummy entry, there by committing the previous log entries.
Both styles serve an important purpose and are useful in different stages of the design and engineering process.
Reasoning Style specifications are concise and allow fast iteration. They are well-suited for exploring core design ideas, proving correctness, and uncovering flaws early. These specs tend to abstract away less relevant operational details and focus on the high-level logic. This not only helps the model checker run faster, but also allows architects and engineers to think clearly about the design space. However, this style can take some getting used to, especially when deciding what to include and what to abstract.
Implementation Style specifications resemble the actual system more closely. They are intuitive for engineers and align well with how people naturally think about implementation. This style is easier to review and is particularly useful when transitioning from design to code. The tradeoff is that these models tend to be more verbose, cover a larger state space, and may take longer to verify exhaustively.
FizzBee is flexible enough to support both styles—use the one that fits your current design goal.