
Raft Consensus Protocol
In this tutorial, we’ll explore how to model the Raft consensus protocol using FizzBee’s actor-based modeling approach. We’ll focus on two main components of Raft: leader election and log replication.
Note: For a comprehensive understanding of Raft, refer to the original Raft paper.
Raft is a consensus algorithm designed to be understandable and implementable. It ensures that a cluster of nodes can agree on a sequence of commands (log entries) even in the presence of failures.
We’ll model Raft in two parts:
- Leader Election: How nodes elect a leader to coordinate actions.
- Log Replication: How the leader ensures that logs are consistently replicated across nodes.
In Raft, nodes can be in one of three states: follower, candidate, or leader. The leader is responsible for managing log replication and coordinating actions among followers. We’ll start by modeling the leader election process.
Generally, we will start with a rough whiteboard diagram or sequence diagram of the system. Since Raft is a well-known algorithm, I’ll use the Raft paper’s summary page as the reference.
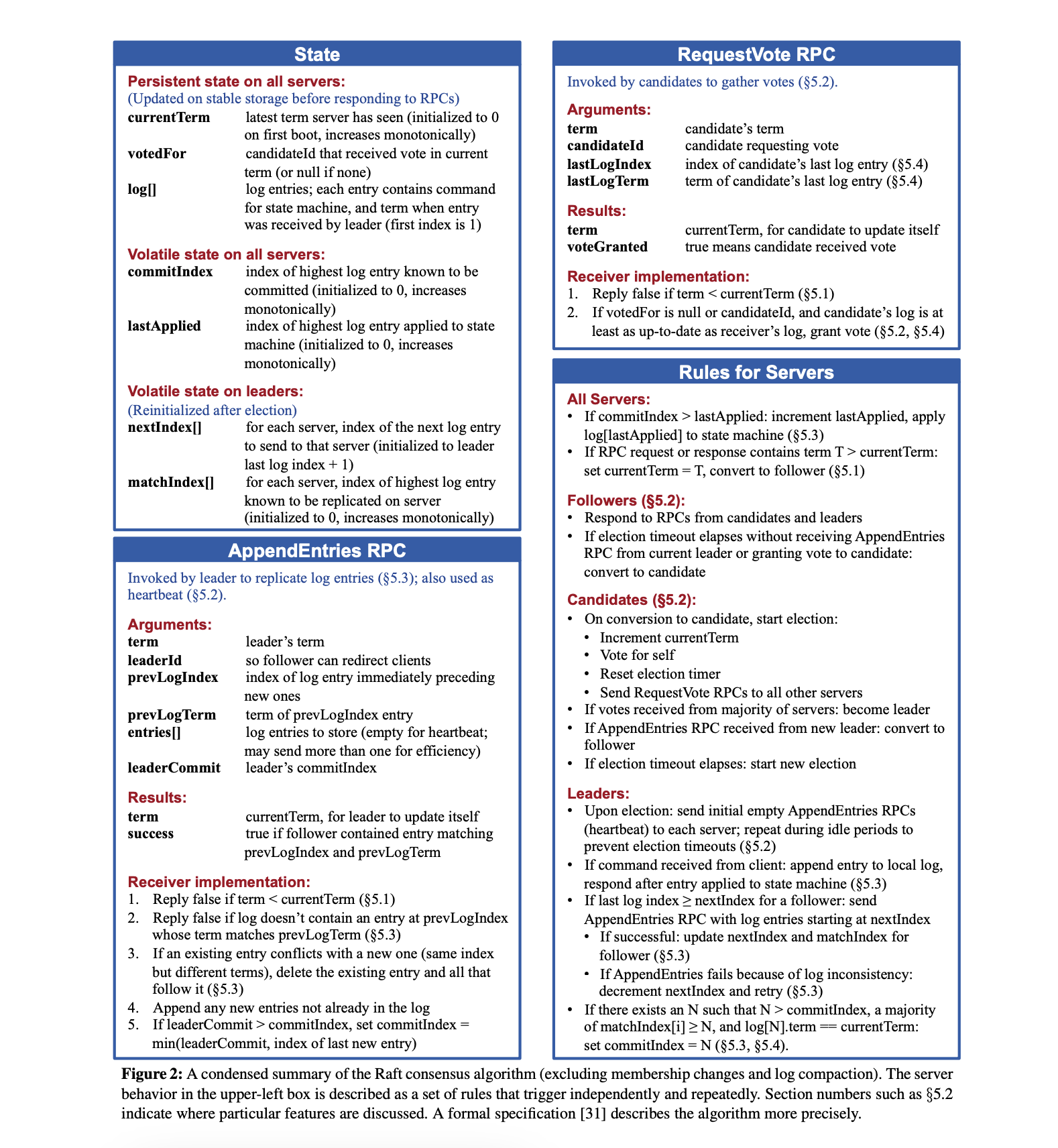
The condensed Summary of the Raft consensus algorithm
There is only one role in this example - the Node.
role Node:
pass

The state variables of each node
Of the states defined in the protocol summary, for leader election we only need,
currentTerm: The current term of the node.votedFor: The candidate that received vote in the current term.mode: The state of the node (follower, candidate, or leader). Themodeis not listed in the protocol summary, but needed to track the state of the node.
Mode = enum("Leader", "Follower", "Candidate")
@state(durable=["currentTerm", "votedFor"])
role Node:
action Init:
self.currentTerm = 0
self.votedFor = None
self.mode = Mode.Follower
|
|
Run the following code in the playgroud.
“Run in playground” will open the snippet in the playground.
Then, click “Enable whiteboard” checkbox and click Run.
The screenshot of the playground highlighting the Enable whiteboard and Run steps
When you run it, you’ll see an The screenshot of the playground highlighting the Explorer link to open the Explorer viewExplorer link. Click you’ll see an explorer.
At present, it will only show the init state. As we start filling in the details, you’ll see more interactive exploration.
RPCs are just functions, with the only difference being these will typically be called from another role. That is, inter-role function calls are treated as RPCs, whereas intra-role function calls are treated as just helper functions.
Functions are defined using func keyword (As opposed to def in python and the self parameter is implicit)
RequestVote: A candidate requests votes from other nodes.AppendEntries: A leader sends log entries to followers. (Mostly needed for log replication, and also for the leader to announce itself as the leader)
role Node:
# other code not shown
func RequestVote(term, candidateId):
pass #To be filled in later
func AppendEntries(term, leaderId):
pass # To be filled in later
Actions are similar to functions, but the only difference is they represent request/event handlers called by external systems whereas functions called by other parts of the model.
In this case, we need to define the following actions:
ElectionTimeout: A timeout event that triggers a new election.SendHeartBeat: A periodic heartbeat sent by the leader to followers.
role Node:
# other code not shown
action ElectionTimeout:
pass
action SendHeartBeat:
pass
Now, we have the basic scaffolding, we could now work on the critical parts of the model.
The rules for RequestVote are as follows:
The RequestVote RPC part of the Raft protocol summary
We’ll also skip the log related parameters.
The first rule from RequestVote RPC’s first rule
Receiver implementation:
- Reply false if term < currentTerm (§5.1)
if term < self.currentTerm:
return False
Then, we will implement the second rule.
Receiver implementation: 2. If votedFor is null or candidateId,
and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
if self.votedFor == None or self.votedFor == candidateId:
atomic:
self.mode = Mode.Follower
self.votedFor = candidateId
return True
return False
Here, the atomic label indicates, there won’t be any yield points in between. Read more about
the block modifiers.
Since in fizzbee, the atomicity is at the statement level by default, the above code is equivalent to with multivariable assignment statement.
if self.votedFor == None or self.votedFor == candidateId:
self.mode, self.votedFor = Mode.Follower, candidateId
return True
Next, from the Rules for Servers’s All Servers section, rule 2.
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
if term > self.currentTerm:
self.currentTerm, self.mode, self.votedFor = term, Mode.Follower, candidateId
return True
The protocol spec doesn’t explicitly mention resetting the votedFor field, but it is implied in the State section.
votedFor candidateId that received vote in current term (or null if none) Since the term changed, the votedFor field should be updated.
Putting together, we have
func RequestVote(term, candidateId):
if term < self.currentTerm:
return False
if term > self.currentTerm:
self.currentTerm, self.mode, self.votedFor = term, Mode.Follower, candidateId
return True
if self.votedFor == None or self.votedFor == candidateId:
self.mode, self.votedFor = Mode.Follower, candidateId
return True
return False # Deny vote
Now, let us implement the ElectionTimeout action.
The ElectionTimeout action part of the Raft protocol summary
As per the spec, if the timeout happens, either the follower or the candidate can start an election.
Leader shouldn’t start an election (leader sends the heartbeat). We can set the precondition using require statement
action ElectionTimeout:
require self.mode != Mode.Leader # Leader does not need to start election
self.mode, self.currentTerm, self.votedFor = \
Mode.Candidate, self.currentTerm + 1, self.__id__
candidate_term, votes = self.currentTerm, 1 # Initialize local variables
# request votes
Then, we need to request votes from other nodes.
for node in nodes:
if node.__id__ != self.__id__:
vote_granted = node.RequestVote(self.currentTerm, self.__id__) # Call RequestVote and store the result
atomic:
if vote_granted:
votes += 1
if votes > NUM_NODES / 2:
break
Finally, we need to check if the candidate has received enough votes to become a leader.
if self.mode == Mode.Candidate and self.currentTerm == candidate_term and votes > NUM_NODES / 2:
self.mode = Mode.Leader
This gives the full ElectionTimeout action
action ElectionTimeout:
require self.mode != Mode.Leader # Leader does not need to start election
# atomic:
# self.mode = Mode.Candidate
# self.currentTerm += 1
# self.votedFor = self.__id__ # Vote for itself
self.mode, self.currentTerm, self.votedFor \
= Mode.Candidate, self.currentTerm + 1, self.__id__
candidate_term, votes = self.currentTerm, 1 # Initialize local variables
for node in nodes:
if node.__id__ != self.__id__:
vote_granted = node.RequestVote(self.currentTerm, self.__id__) # Call RequestVote and store the result
atomic:
if vote_granted:
votes += 1
if votes > NUM_NODES / 2:
break
if self.mode == Mode.Candidate and self.currentTerm == candidate_term and votes > NUM_NODES / 2:
self.mode = Mode.Leader
always assertion AtMostOneLeaderPerTerm:
for term_val in set([node.currentTerm for node in nodes]):
leaders_in_term = [node for node in nodes if node.mode == Mode.Leader and node.currentTerm == term_val]
if len(leaders_in_term) > 1:
return False
return True
|
|
Open this code in the playground, enable the whiteboard and run. Things should pass. You can open the explorer to interactively explore various scenarios.
In the fizzbee spec, you’ll see the RequestVote RPC is sent in a sequential for loop. We can parallelize this.
This is done by using the parallel modifier to the for loop.
@@ -1,2 +1,3 @@
- for node in nodes:
- # stmts
+ parallel for node in nodes:
+ serial:
+ # stmts
parallel for node in nodes:
serial:
if node.__id__ != self.__id__:
vote_granted = node.RequestVote(self.currentTerm, self.__id__) # Call RequestVote and store the result
atomic:
if vote_granted:
votes += 1
if votes > NUM_NODES / 2:
break
When you run with this change and explore the leader election, when it comes to the loop, you’ll see these extra buttons to be able to choose the order of iterations.
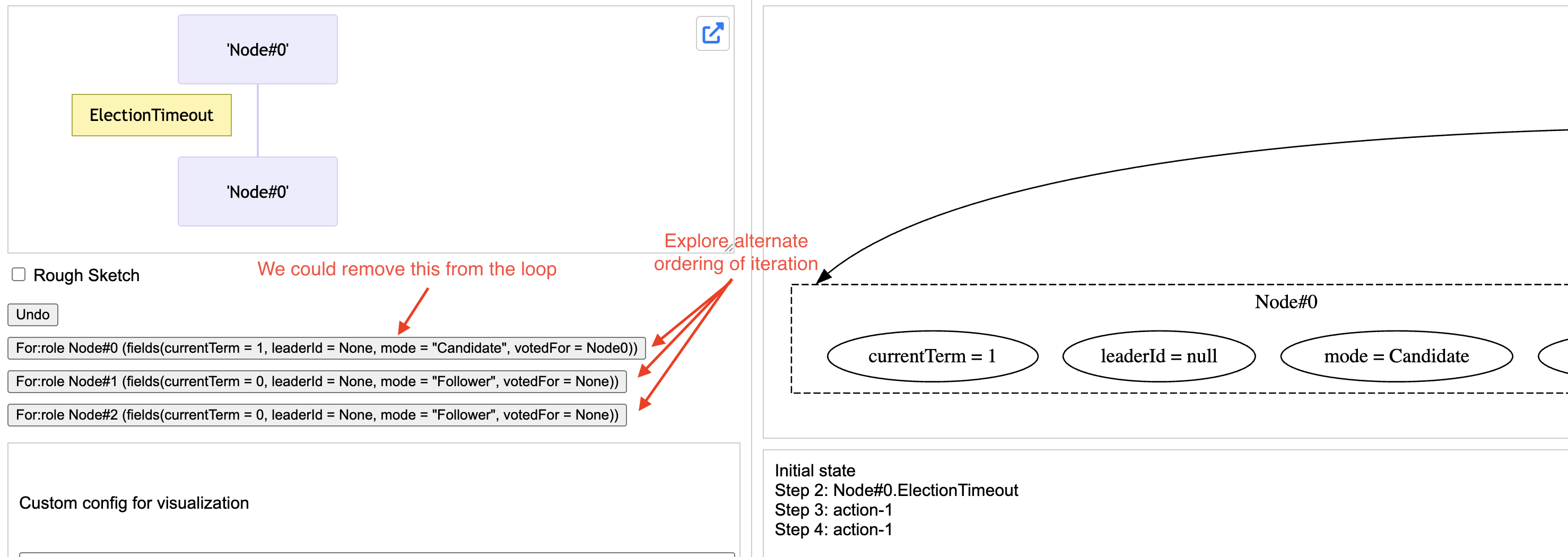
Choose the order of iterations
You’ll also notice an extra unnecessary loop that gets skipped anyway with the if statement. You can use the classic python loop comprehension to simply this and remove the if statement as well.
@@ -1,6 +1,5 @@
- parallel for node in nodes:
+ parallel for node in [n for n in nodes if n.__id__ != self.__id__]:
serial:
- if node.__id__ != self.__id__:
vote_granted = node.RequestVote(self.currentTerm, self.__id__) # Call RequestVote and store the result
atomic:
if vote_granted:
Or alternatively have a helper function like,
@@ -1,9 +1,11 @@
- parallel for node in nodes:
+ parallel for node in other_nodes(nodes, self)
serial:
- if node.__id__ != self.__id__:
vote_granted = node.RequestVote(self.currentTerm, self.__id__) # Call RequestVote and store the result
atomic:
if vote_granted:
votes += 1
if votes > NUM_NODES / 2:
break
+
+def other_nodes(nodes, node):
+ return [n for n in nodes if n.__id__ != node.__id__]
func AppendEntries(leaderTerm, leaderId):
if leaderTerm >= self.currentTerm:
self.currentTerm, self.mode, self.leaderId \
= leaderTerm, Mode.Follower, leaderId
return True # Acknowledge heartbeat
else:
return False # Reject heartbeat
action SendHeartBeat:
require self.mode == Mode.Leader
for node in nodes:
if node.__id__ != self.__id__:
node.AppendEntries(self.currentTerm, self.__id__)
When you try the interactive explorer, you can reproduce the leader announcement step, for example, a sample sequence diagram would look like this.
sequenceDiagram note left of 'Node#0': ElectionTimeout 'Node#0' ->> 'Node#1': RequestVote(term: 1, candidateId: Node0) 'Node#1' -->> 'Node#0': (True) note left of 'Node#0': SendHeartbeat 'Node#0' ->> 'Node#1': AppendEntries(leaderTerm: 1, leaderId: Node0) 'Node#1' -->> 'Node#0': (True) 'Node#0' ->> 'Node#2': AppendEntries(leaderTerm: 1, leaderId: Node0) 'Node#2' -->> 'Node#0': (True)
|
|
The step-by-step guide to modeling Raft’s log replication is in progress. In the meantime, you can take a look at the final full spec.
We don’t need any new roles, we will work with the same role Node
From the specs,
The Log Replication states part of the Raft protocol summary
Of these, only the log is durable.
@@ -1,7 +1,12 @@
-@state(durable=["currentTerm", "votedFor"])
+@state(durable=["currentTerm", "votedFor", "log"])
role Node:
action Init:
self.currentTerm = 0
self.votedFor = None
self.mode = Mode.Follower
self.leaderId = None
+ self.log = [(0, "")] # List of log entries (command, term), with sentinel
+ self.commitIndex = 0
+ self.lastApplied = 0
+ self.nextIndex = {} # Only for leader, reinitialized after each election
+ self.matchIndex = {} # Only for leader, reinitialized after each election
From the spec from the raft paper,
The RequestVote RPC part of the Raft protocol summary
lastLogIndex and lastLogTerm to the RequestVote RPC. And, update the rule to
grant vote only if candidate’s log is at least as uptodate as the receiver’s log.
@@ -1,10 +1,12 @@
- func RequestVote(term, candidateId):
+ atomic func RequestVote(term, candidateId, lastLogIndex, lastLogTerm):
if term < self.currentTerm:
return False
if term > self.currentTerm:
- self.currentTerm, self.mode, self.votedFor = term, Mode.Follower, candidateId
- return True
+ self.currentTerm, self.mode, self.votedFor = term, Mode.Follower, None
if self.votedFor == None or self.votedFor == candidateId:
- self.mode, self.votedFor = Mode.Follower, candidateId
- return True
+ if lastLogTerm > self.log[-1][0] or (
+ lastLogTerm == self.log[-1][0] and lastLogIndex >= len(self.log)):
+ self.mode, self.votedFor = Mode.Follower, candidateId
+ return True
+
return False # Deny vote
And update the usage in the ElectionTimeout action.
@@ -6,12 +6,17 @@
for node in other_nodes(nodes, self):
serial:
- vote_granted = node.RequestVote(self.currentTerm, self.__id__)
+ vote_granted = node.RequestVote(self.currentTerm, self.__id__, len(self.log), self.log[-1][0])
atomic:
if vote_granted:
votes += 1
if votes > NUM_NODES / 2:
break
- if self.mode == Mode.Candidate and self.currentTerm == candidate_term and votes > NUM_NODES / 2:
- self.mode = Mode.Leader
+ atomic:
+ if self.mode == Mode.Candidate and self.currentTerm == candidate_term and votes > NUM_NODES / 2:
+ self.mode = Mode.Leader
+ for node in nodes:
+ if node != self:
+ self.nextIndex[node.__id__] = len(self.log)
+ self.matchIndex[node.__id__] = 0
From the rules from the spec,

The AppendEntries RPC part of the Raft protocol summary
@@ -1,4 +1,4 @@
- func AppendEntries(term, leaderId):
+ func AppendEntries(term, leaderId, prevLogIndex, prevLogTerm, entries, leaderCommit):
And the implementation of the AppendEntries RPC
func AppendEntries(leaderTerm, leaderId, prevLogIndex, prevLogTerm, entries, leaderCommit):
if leaderTerm > self.currentTerm:
# If RPC request or response contains term T > currentTerm:
# set currentTerm = T, convert to follower (§5.1)
atomic:
self.currentTerm = leaderTerm
self.mode = Mode.Follower # Convert to follower
self.leaderId = leaderId # Setting the leader id
# 1. Reply false if term < currentTerm (§5.1)
if leaderTerm < self.currentTerm:
return False
# 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
if prevLogIndex > len(self.log) - 1 or self.log[prevLogIndex][0] != prevLogTerm:
return False
# 3. If an existing entry conflicts with a new one (same index but different terms),
# delete the existing entry and all that follow it (§5.3)
atomic:
for i in range(len(entries)):
logIndex = prevLogIndex + i + 1
if logIndex < len(self.log) and self.log[logIndex][0] != entries[i][0]:
self.log = self.log[:logIndex] # Delete existing entry and all that follow it
# 4. Append any new entries not already in the log
atomic:
for i in range(len(entries)):
logIndex = prevLogIndex + i + 1
if logIndex >= len(self.log):
self.log.append(entries[i])
# 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if leaderCommit > self.commitIndex:
self.commitIndex = min(leaderCommit, len(self.log) - 1)
return True
@@ -1,6 +1,12 @@
action SendHeartbeat:
require self.mode == Mode.Leader # Only leader can send heartbeat
- term = self.currentTerm
for node in nodes:
+ atomic:
if node != self:
- node.AppendEntries(term, self.__id__)
+ prevLogIndex = self.nextIndex[node.__id__] - 1
+ if prevLogIndex >= len(self.log) or prevLogIndex < 0:
+ continue
+ prevLogTerm = self.log[prevLogIndex][0]
+ entries = self.log[self.nextIndex[node.__id__]:]
+ node.AppendEntries(self.currentTerm, self.__id__, prevLogIndex, prevLogTerm, entries, self.commitIndex)
action SubmitCommand:
require self.mode == Mode.Leader
nextCmd, entry, success_count, success, newLogIndex = nextCmd + 1, (self.currentTerm, "cmd" + str(nextCmd)), 1, False, len(self.log)
self.log.append(entry)
# Replicate to followers
for node in nodes:
if node != self:
atomic:
prevLogIndex = self.nextIndex[node.__id__] - 1
if prevLogIndex >= len(self.log) or prevLogIndex < 0:
continue
# prevLogTerm, entries = self.log[prevLogIndex][0], [(self.currentTerm, command)]
prevLogTerm, entries = self.log[prevLogIndex][0], self.log[prevLogIndex+1:]
# entries = [(self.currentTerm, command)] # Only send the new entry
success = node.AppendEntries(self.currentTerm, self.__id__, prevLogIndex, prevLogTerm, entries, self.commitIndex)
atomic:
if success:
success_count += 1
self.nextIndex[node.__id__] = newLogIndex + 1
self.matchIndex[node.__id__] = newLogIndex
# Check if majority of nodes have replicated the log
if success_count > NUM_NODES / 2:
self.commitIndex = newLogIndex
# TODO: Apply the command to the state machine
|
|